
Panopticon is a prison design where the guard tower can see every cell and every inmate at all times, while inmates cannot see if they are being watched.

Panopticon is also the term used for the theoretical upper limit for a dataset of all text spoken and written by every human on Earth. How much data would that be on a disk?
If Joe is average, and in one day he:
writes three emails, one with an attached document
sends ten text messages
talks on the phone for thirty minutes
talks and writes offline for three hours
The text from all that activity adds up to about one megabyte.12 Multiply by 8 billion people on Earth and that’s about 5 petabytes of natural language plain text, daily.
How does that compare to the amount of text that is used to train large language models (LLMs) like ChatGPT?
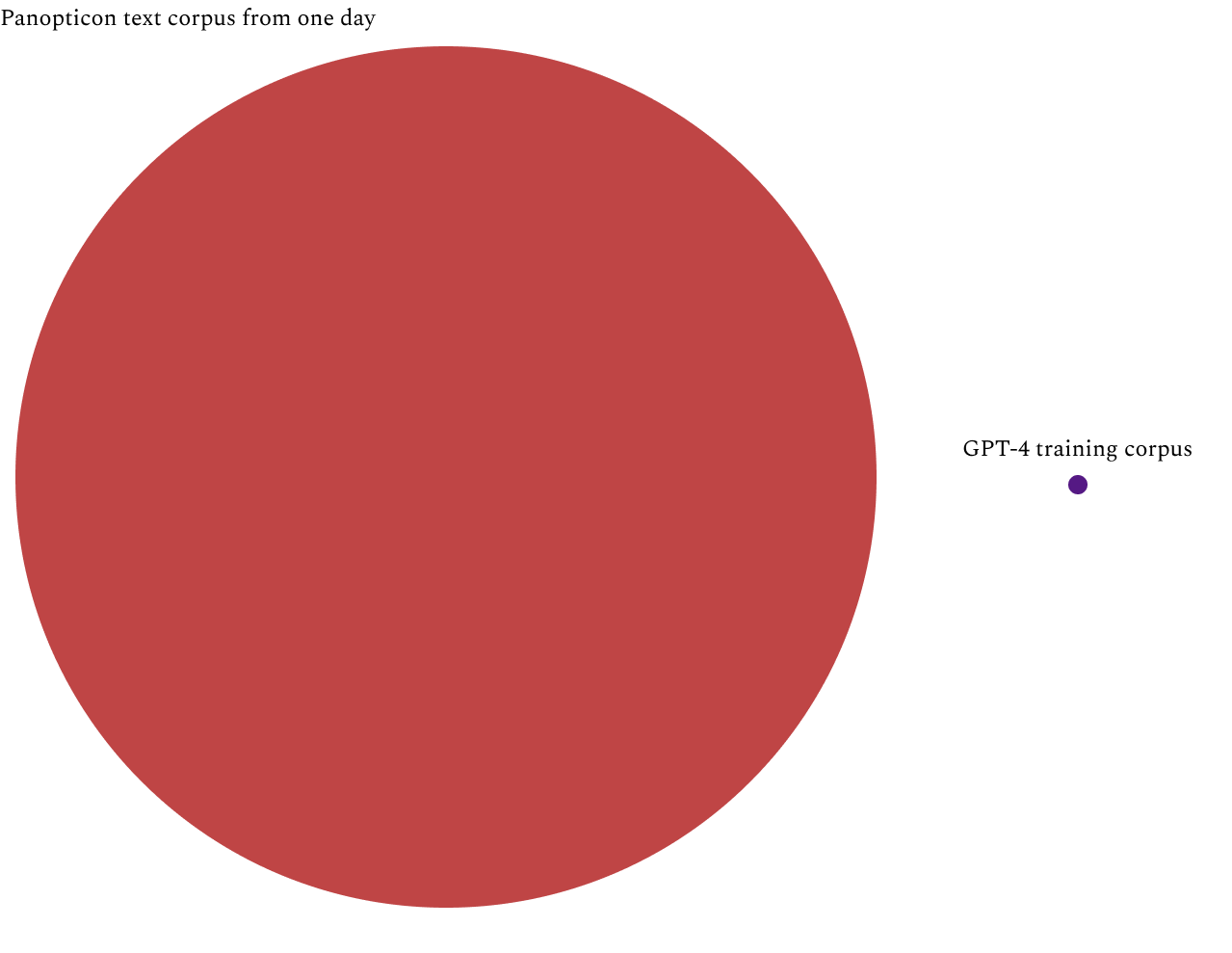
GPT-4 was announced on March 14, 2023. OpenAI released a technical paper but it did not include the size of the training set. The previous version, GPT-3, was trained on a corpus of 570 gigabytes of plain text, which was roughly ten times larger than the dataset GPT-2 was trained on. GPT-2’s training set was about ten times larger than GPT-1. If we assume 10x growth, then perhaps GPT-4 was trained on 5 terabytes of text.3 That is equivalent to 0.05% of one day of Panopticon.4
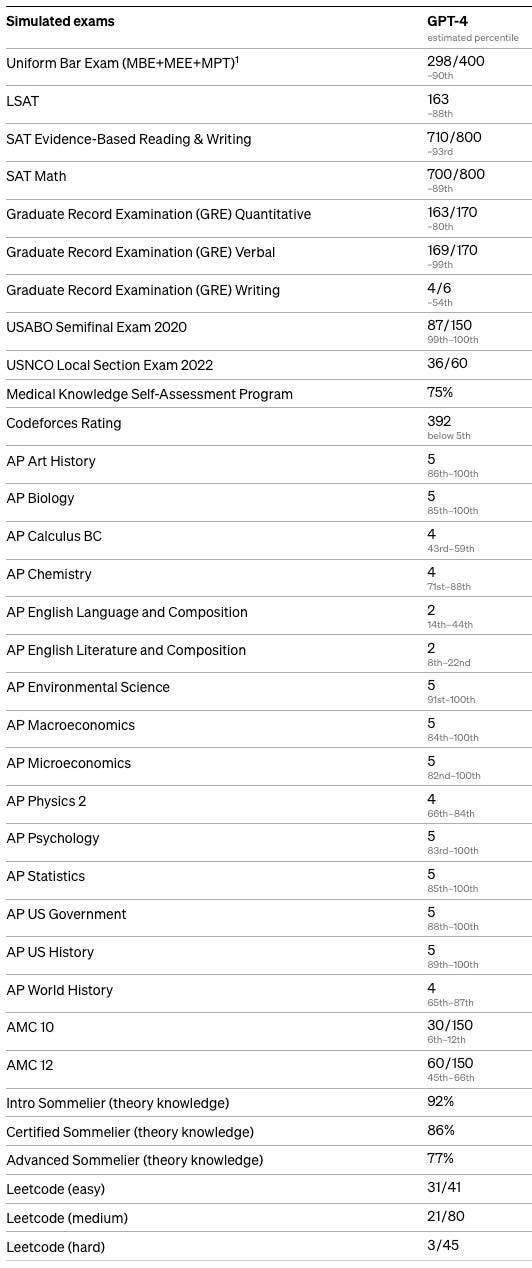
GPT-4 performs well enough on standardized tests to apply to Stanford:
Maybe it shouldn’t be surprising that an AI can get smart by reading “just” a few terabytes of text. We know humans read much less than that and some of them are really smart. If you read the equivalent of 60 books a year, for 60 years, that would be about 3.6 gigabytes of text.5 That’s about one one-thousandth of GPT-4’s corpus size.
There are perverse incentives to build towards a Panopticon dataset: greed and power. It’s safe to assume the Chinese Communist Party is pursuing it. Uyghurs would say it's already here.6 Every other intelligence agency, finanicial insitution, and major tech company will be on that path.
Most of a panopticon text corpus would be useless babble, and it would be incredibly expensive to manage. But that may not stop people from trying to build it.
Data collectors have an asymmetric advantage over the rest of us. It’s easy to collect data on people and not be seen doing it. It gets easier every year. I remember joining a company and being shown an app called FullStory which replays user sessions. Our users had no idea they were being recorded. We could see, in real-time, how they moved their mouse, what pages they visited, and what they typed. It’s a toy example, but it was creepy.
Every year more and better sensors occupy our day-to-day spaces, capturing our conversations, movement, and transactions. These things are convenient. Most of these devices connect to the internet. We’re all feeding the beast.
The wheels of capitalism turn in boring office meetings, marketing slide shows, and analytics dashboards. The latest and greatest AI models train on ever-growing data streams, spinning on GPUs in sterile server farms, while executives and leaders rotate in and out of these projects with almost zero accountability.
When I interact with GPT-4, it feels like we are summoning a demon or an alien has landed. Its appetite for data grows and grows. I find myself wanting to read a book and not think about it.
Size estimates for text messages and emails are from: https://www.xfinity.com/support/articles/what-1gb-data-means. Other assumptions are Joe’s conversations are 125 words per minute, and 125,000 words equals one megabyte.
Estimate of the rate of information in human speech. https://www.science.org/content/article/human-speech-may-have-universal-transmission-rate-39-bits-second
OpenAI’s competitors have released models that approach GPT-3’s level of performance, using fewer parameters and datasets that are smaller. 5 terabytes might be an overestimate.
1000 terabytes = 1 petabyte. 5 TB divided by 10 PB = 0.05%.
Assuming one book equals one megabyte of text, or about 500 pages.
The Atlantic published this article about China’s version of panopticon https://www.theatlantic.com/magazine/archive/2020/09/china-ai-surveillance/614197/